
Giải thuật tìm kiếm A*
| Thuật toán tìm kiếm cây và đồ thị |
|---|
| Danh sách |
| Liên quan |
Trong khoa học máy tính, A* (đọc là A sao) là thuật toán tìm kiếm trong đồ thị. Thuật toán này tìm một đường đi từ một nút khởi đầu tới một nút đích cho trước (hoặc tới một nút thỏa mãn một điều kiện đích). Thuật toán này sử dụng một "đánh giá heuristic" để xếp loại từng nút theo ước lượng về tuyến đường tốt nhất đi qua nút đó. Thuật toán này duyệt các nút theo thứ tự của đánh giá heuristic này. Do đó, thuật toán A* là một ví dụ của tìm kiếm theo lựa chọn tốt nhất (best-first search).
Thuật toán A* được mô tả lần đầu vào năm 1968 bởi Peter Hart, Nils Nilsson, và Bertram Raphael. Trong bài báo của họ, thuật toán được gọi là thuật toán A; khi sử dụng thuật toán này với một đánh giá heuristic thích hợp sẽ thu được hoạt động tối ưu, do đó mà có tên A*.
Năm 1964, Nils Nilsson phát minh ra một phương pháp tiếp cận dựa trên khám phá để tăng tốc độ của thuật toán Dijkstra. Thuật toán này được gọi là A1. Năm 1967 Bertram Raphael đã cải thiện đáng kể thuật toán này, nhưng không thể hiển thị tối ưu. Ông gọi thuật toán này là A2. Sau đó, trong năm 1968 Peter E. Hart đã giới thiệu một đối số chứng minh A2 là tối ưu khi sử dụng thuật toán này với một đánh giá heuristic thích hợp sẽ thu được hoạt động tối ưu. Chứng minh của ông về thuật toán cũng bao gồm một phần cho thấy rằng các thuật toán A2 mới là thuật toán tốt nhất có thể được đưa ra các điều kiện. Do đó ông đặt tên cho thuật toán mới là A *(A sao, A-star).
Ý tưởng trực quan[sửa | sửa mã nguồn]
Xét bài toán tìm đường - bài toán mà A* thường được dùng để giải. A* xây dựng tăng dần tất cả các tuyến đường từ điểm xuất phát cho tới khi nó tìm thấy một đường đi chạm tới đích. Tuy nhiên, cũng như tất cả các thuật toán tìm kiếm có thông tin (informed tìm kiếm thuật toán), nó chỉ xây dựng các tuyến đường "có vẻ" dẫn về phía đích.
Để biết những tuyến đường nào có khả năng sẽ dẫn tới đích, A* sử dụng một "đánh giá heuristic" về khoảng cách từ điểm bất kỳ cho trước tới đích. Trong trường hợp tìm đường đi, đánh giá này có thể là khoảng cách đường chim bay - một đánh giá xấp xỉ thường dùng cho khoảng cách của đường giao thông.
Điểm khác biệt của A* đối với tìm kiếm theo lựa chọn tốt nhất là nó còn tính đến khoảng cách đã đi qua. Điều đó làm cho A* "đầy đủ" và "tối ưu", nghĩa là, A* sẽ luôn luôn tìm thấy đường đi ngắn nhất nếu tồn tại một đường đi như vậy. A* không đảm bảo sẽ chạy nhanh hơn các thuật toán tìm kiếm đơn giản hơn. Trong một môi trường dạng mê cung, cách duy nhất để đến đích có thể là trước hết phải đi về phía xa đích và cuối cùng mới quay lại. Trong trường hợp đó, việc thử các nút theo thứ tự "gần đích hơn thì được thử trước" có thể gây tốn thời gian.
Mô tả thuật toán[sửa | sửa mã nguồn]

A* lưu giữ một tập các lời giải chưa hoàn chỉnh, nghĩa là các đường đi qua đồ thị, bắt đầu từ nút xuất phát. Tập lời giải này được lưu trong một hàng đợi ưu tiên (priority queue). Thứ tự ưu tiên gán cho một đường đi được quyết định bởi hàm .


Trong đó, là chi phí của đường đi cho đến thời điểm hiện tại, nghĩa là tổng trọng số của các cạnh đã đi qua. là hàm đánh giá heuristic về chi phí nhỏ nhất để đến đích từ . Ví dụ, nếu "chi phí" được tính là khoảng cách đã đi qua, khoảng cách đường chim bay giữa hai điểm trên một bản đồ là một đánh giá heuristic cho khoảng cách còn phải đi tiếp.


Hàm có giá trị càng thấp thì độ ưu tiên của càng cao (do đó có thể sử dụng một cấu trúc heap tối thiểu để cài đặt hàng đợi ưu tiên này)

function A*(điểm_xuất_phát,đích)
var đóng:= tập rỗng
var q:= tạo_hàng_đợi(tạo_đường_đi(điểm_xuất_phát))
while q không phải tập rỗng
var p:= lấy_phần_tử_đầu_tiên(q)
var x:= nút cuối cùng của p
if x in đóng
continue
if x = đích
return p
bổ sung x vào tập đóng
foreach y in các_đường_đi_tiếp_theo(p)
đưa_vào_hàng_đợi(q, y)
return failure
Trong đó, các_đường_đi_tiếp_theo(p) trả về tập hợp các đường đi tạo bởi việc kéo dài p thêm một nút kề cạnh. Giả thiết rằng hàng đợi được sắp xếp tự động bởi giá trị của hàm .

"Tập hợp đóng" (đóng) lưu giữ tất cả các nút cuối cùng của p (các nút mà các đường đi mới đã được mở rộng tại đó) để tránh việc lặp lại các chu trình (việc này cho ra thuật toán tìm kiếm theo đồ thị). Đôi khi hàng đợi được gọi một cách tương ứng là "tập mở". Tập đóng có thể được bỏ qua (ta thu được thuật toán tìm kiếm theo cây) nếu ta đảm bảo được rằng tồn tại một lời giải hoặc nếu hàm các_đường_đi_tiếp_theo được chỉnh để loại bỏ các chu trình.
Các tính chất[sửa | sửa mã nguồn]
Cũng như tìm kiếm theo chiều rộng (breadth-first search), A* là thuật toán đầy đủ (complete) theo nghĩa rằng nó sẽ luôn luôn tìm thấy một lời giải nếu bài toán có lời giải.
Nếu hàm heuristic có tính chất thu nạp được (admissible), nghĩa là nó không bao giờ đánh giá cao hơn chi phí nhỏ nhất thực sự của việc đi tới đích, thì bản thân A* có tính chất thu nạp được (hay tối ưu) nếu sử dụng một tập đóng. Nếu không sử dụng tập đóng thì hàm phải có tính chất đơn điệu (hay nhất quán) thì A* mới có tính chất tối ưu. Nghĩa là nó không bao giờ đánh giá chi phí đi từ một nút tới một nút kề nó cao hơn chi phí thực. Phát biểu một cách hình thức, với mọi nút trong đó là nút tiếp theo của :




A* còn có tính chất hiệu quả một cách tối ưu (optimally efficient) với mọi hàm heuristic , có nghĩa là không có thuật toán nào cũng sử dụng hàm heuristic đó mà chỉ phải mở rộng ít nút hơn A*, trừ khi có một số lời giải chưa đầy đủ mà tại đó dự đoán chính xác chi phí của đường đi tối ưu.
Bài toán minh họa[sửa | sửa mã nguồn]
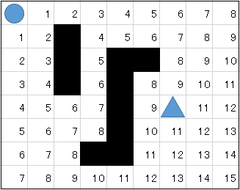
Cho một bàn cờ kích thước n x n. Hãy tìm đường đi ngắn nhất từ điểm 〇 đến điểm △ biết rằng
- Các ô trắng là đường đi
- Các ô đen là vật cản, không đi được
- Tại một ô bất kỳ, chỉ có thể đi lên, xuông, trái, phải nếu không bị cản. Không được đi chéo
-
 Bàn cờ với kích thước 9*8
Bàn cờ với kích thước 9*8

Trong bài toán trên ta thấy rằng đường đi ngắn nhất là đường chéo nối từ 〇 đến △
chiều dài đường chéo được tính bằng công thức

Khi di chuyển qua mỗi ô thì giá trị của ô sẽ tăng lên 1 đơn vị
-
 g(x)
g(x) -




vì là nên ta có bảng như sau:

Tiếp theo từ vị trí 0 sẽ duyệt các ô lân cận nó để tìm ra đường ngắn nhất
Ví dụ
Xét lại điểm P(0,0) thì có 2 điểm liên kề nó là bên phải P(1,0) và bên dưới P(0,1) và giá trị

vì 2 giá trị bằng nhau nên chọn điểm nào cũng được. Ở Step 2 thì đang chọn điểm P(1,0)
Điểm P(1,0) có 2 điểm liền kề có giá trị lần lượt là: công với P(0,1) đang có sẵn thì ta có 3 điểm


Theo mình, hàm đánh giá ở ví dụ trên tính sai và so sánh giữa 2 giá trị f(x) và h(x) là khác nhau nên việc so sánh 2 giá trị đó là sai. Đồng thời node cần di chuyển tới là node có giá trị hàm f(x) nhỏ nhất, chứ không phải gần giá trị f(x) của node đích (ở ví dụ trên là h(x) tại node đích là 8.6). Các bạn cần tham khảo thêm tài liệu, tránh sai sót khi chỉ tìm kiếm trên wikipedia. uet maidinh
Giá trị là giá trị gần với giá trị 8.6 nhất. nên P(2,0) được chọn làm giá trị xét tiếp theo. tương tự các bước trên ta được bảng như dưới.


Sau khi chạm được đến điểm △ thì ta được sơ đồ đường đi ngắn nhất như sau:

Quan hệ với tìm kiếm chi phí đều (uniform-cost search)[sửa | sửa mã nguồn]
Thuật toán Dijkstra là một trường hợp đặc biệt của A* trong đó đánh giá heuristic là một hàm hằng với mọi .

Độ phức tạp thuật toán[sửa | sửa mã nguồn]
Độ phức tạp thời gian của A* phụ thuộc vào đánh giá heuristic. Trong trường hợp xấu nhất, số nút được mở rộng theo hàm mũ của độ dài lời giải, nhưng nó sẽ là hàm đa thức khi hàm heuristic h thỏa mãn điều kiện sau:

trong đó là heuristic tối ưu, nghĩa là hàm cho kết quả là chi phí chính xác để đi từ tới đích. Nói cách khác, sai số của h không nên tăng nhanh hơn lôgarit của "heuristic hoàn hảo" - hàm trả về khoảng cách thực từ x tới đích (Russell và Norvig 2003, tr. 101).

Vấn đề sử dụng bộ nhớ của A* còn rắc rối hơn độ phức tạp thời gian. Trong trường hợp xấu nhất, A* phải ghi nhớ số lượng nút tăng theo hàm mũ. Một số biến thể của A* đã được phát triển để đối phó với hiện tượng này, một trong số đó là A* lặp sâu dần (iterative deepening A*), A* bộ nhớ giới hạn (memory-bounded A* - MA*) và A* bộ nhớ giới hạn đơn giản (simplified memory bounded A*).
Một thuật toán tìm kiếm có thông tin khác cũng có tính chất tối ưu và đầy đủ nếu đánh giá heuristic của nó là thu nạp được (admissible). Đó là tìm kiếm đệ quy theo lựa chọn tốt nhất (recursive best-first search - RBFS).
Tham khảo[sửa | sửa mã nguồn]
- Hart, P. E. (1968). Nilsson, N. J.; Raphael, B. “A Formal Basis for the Heuristic Determination of Minimum Cost Paths”. IEEE Transactions on Systems Science and Cybernetics SSC4 (2): 100–107.
- Hart, P. E. (1972). Nilsson, N. J.; Raphael, B. “Correction to "A Formal Basis for the Heuristic Determination of Minimum Cost Paths"”. SIGART Newsletter. 37: 28–29.
- Nilsson, N. J. (1980). Principles of Artificial Intelligence. Palo Alto, California: Tioga Publishing Company.
- Russell, S. J. (2003). Artificial Intelligence: A Modern Approach. Norvig, P. tr. 97-104.
Liên kết ngoài[sửa | sửa mã nguồn]
Tiếng Anh:
- Justin Heyes-Jones' A* algorithm tutorial
- Herbert Glarner's Interactive Single Step Simulation in VB 6.0[liên kết hỏng], implemented as a DLL, including a GUI allowing simulation in user-defined grids.
- Another A* Pathfinding for Beginners Lưu trữ 2005-12-24 tại Wayback Machine (note: incorrectly states that A* always needs a "closed set")
- Amit's Thoughts on Path-Finding and A*
- Sven Koenig's Demonstration of Lifelong Planning A* and A*
- Tony Stentz's Papers on D* (Dynamic A*) Path-Finding Lưu trữ 2006-09-12 tại Wayback Machine
- Remko Tronçon and Joost Vennekens's JSearch demo Lưu trữ 2006-07-15 tại Wayback Machine: demonstrates various search algorithms, including A*.
- Sune Trudslev's Path finding in C# article Lưu trữ 2006-07-21 tại Wayback Machine